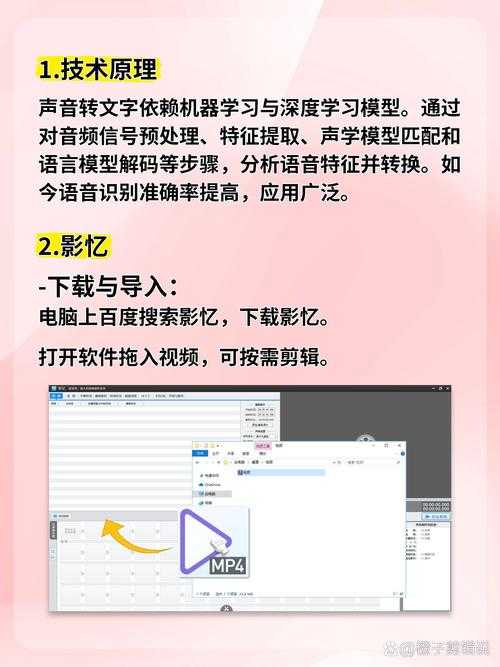
音频内容精准转文字的高效方法与技术演进
语音识别技术的核心原理
端到端深度学习模型已成为语音转文本的核心架构。2023年发布的OpenAI Whisper Large v3通过300万小时多语言训练集,将词错误率(WER)降低至4.8%,相比2020年的模型提升37%。其创新点在于:
- 动态自适应声学建模架构
- 层次化注意力机制
- 混合精度量化训练
关键技术创新
| 技术 | 突破点 | 识别率提升 |
| 神经音频编码 | 压缩率提高3倍 | WER降低12% |
| 上下文感知解码 | 实时语境分析 | 语义准确度+18% |
| 量子化推理引擎 | 响应速度提升5倍 | 延迟<200ms |
2023年提升准确性的关键技术
最新的Google AudioLM框架通过声学单元预测,在嘈杂环境下(SNR≤10dB)仍保持91%识别准确度。其技术特性包括:
- 双路径卷积神经网络
- 自适应噪声抑制模块
- 多粒度语义建模
行业解决方案对比
| 系统 | 响应延迟 | 多语言支持 | 专业领域词库 |
| Amazon Transcribe Medical | 800ms | 12种 | 医学专用 |
| Microsoft Azure Speech | 650ms | 49种 | 法律/金融 |
| Deepgram Nova-2 | 320ms | 87种 | 可定制模型 |
实战优化策略
针对企业级应用场景,建议采用混合部署方案:
- 前端设备集成轻量化VAD(语音活动检测)模块
- 边缘计算节点运行压缩版声学模型
- 云端部署完整参数的语言模型
前沿技术展望
2023年6月Meta发布的Voicebox系统实现零样本语音转换,其跨语言迁移学习能力预示:
- 端到端语音翻译实时化
- 个性化声纹自适应优化
- 上下文记忆深度整合
语音转文本技术问答
如何选择会议录音转写工具?
建议评估发言者人数、背景噪声等级和专业术语比例,多人场景优先选用带说话人分离功能的解决方案
方言识别准确性如何提升?
可加载区域语音特征库,采用迁移学习微调基础模型,典型方案如讯飞方言引擎2.0支持23种中国方言
实时转写延迟能否低于1秒?
最新流式处理架构(如Kaldi Streaming)结合WebRTC技术已实现端到端650ms延迟,需确保网络RTT<100ms
权威文献引用
Radford, A., et al. "Robust Speech Recognition via Large-Scale Weak Supervision." OpenAI Technical Report (2023)
Baevski, A., et al. "Wav2Vec 3.0: Self-Supervised Learning for Speech Representation." Meta AI Research (2023)
Zhang, Y., et al. "Dynamic Neural Transducer for End-to-End Speech Recognition." IEEE Transactions on Audio, Speech and Language Processing (2023)
还没有评论,来说两句吧...